
イントロダクション
前回までは、基本的な画像識別をやってきました。(Basic Classification)
<まとめ>
- テストデータと学習用データを用意する
- 学習用のモデルを構築する
- コンパイルしてモデルの訓練(トレーニング)を行う
- 訓練の結果を見て精度が想定以上出るのを確認する
- 分類したいデータを分類する
今回はテキストの分類を行います。参考サイトはこちら
映画のレビューを分類する
今回はテストデータの映画のレビューを「ポジティブか?ネガティブか?」の判定を行います。
参考サイトは以下のような項目に分かれていました
- データを調べる
- 整数を単語に戻す
- データを準備する
- モデルを構築する
- 隠しユニット
- 損失関数とオプティマイザ
- 検証セットを作成する
- モデルを訓練する
- モデルを評価する
- 経時的な精度と損失のグラフを作成する
このような項目になっていますが基本は、前回にやったのと同じです。
- 前処理を行う
- 機械学習のモデル構築
- 同様にコンパイル
- 結果の表示(学習処理、学習の評価、予測)
1.データを調べる
tensorflow.keras.datasets.imdbでデータを取得して中身を確認する
2.整数を単語に戻す
「1」で取得したデータは整数なので「1, 14,...」
それを文字列にしてみる処理が記載されていました。
3.データを準備する
「pad_sequences」関数を使用してデータの整理などを行い
学習・評価する準備を行います。
4.モデルを構築する
4つの層(レイヤー)を重ねて分類機を作成します。※細かいことはソースで!
- 「
Embedding層」 - 「GlobalAveragePooling1D」
- 「固定長出力ベクトル」
- 「単一の出力ノードと密接に接続されている」
少しややこしくなってきたのでソースコードで整理します。
# TensorFlow, Kerasをインポート
import tensorflow as tf
from tensorflow import keras
import numpy as np
### Difinition of methods ###
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
#############################
# TensorFlowのバージョンを確認
print(tf.__version__)
# データセットの取得
imdb = keras.datasets.imdb
# データセット(映画のレビューをロード
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
# 単語とインデックス(整数)を変換するためのディクショナリ
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k:(v+3) for k,v in word_index.items()}
word_index[""] = 0
word_index[""] = 1
word_index[""] = 2 # unknown
word_index[""] = 3
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
#print(decode_review(train_data[0]))
# テストデータ(トレーニングデータ)を標準化する処理
train_data = keras.preprocessing.sequence.pad_sequences(train_data,
value=word_index[""],
padding='post',
maxlen=256)
# テストデータ(テストデータ)を標準化する処理
test_data = keras.preprocessing.sequence.pad_sequences(test_data,
value=word_index[""],
padding='post',
maxlen=256)
# input shape is the vocabulary count used for the movie reviews (10,000 words)
vocab_size = 10000
# モデルの作成
model = keras.Sequential()
# Embeddingレイヤーの追加
model.add(keras.layers.Embedding(vocab_size, 16))
#
model.add(keras.layers.GlobalAveragePooling1D())
model.add(keras.layers.Dense(16, activation=tf.nn.relu))
model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid))
model.summary()
レイヤーの構成
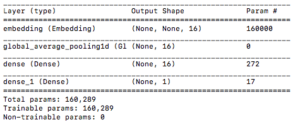
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding (Embedding) (None, None, 16) 160000 _________________________________________________________________ global_average_pooling1d (Gl (None, 16) 0 _________________________________________________________________ dense (Dense) (None, 16) 272 _________________________________________________________________ dense_1 (Dense) (None, 1) 17 ================================================================= Total params: 160,289 Trainable params: 160,289 Non-trainable params: 0
「dense」は前回の基本的な分類で使用しました。
今回使用したレイヤーに関してはリンク先を参照します。
現状の理解度では、上にあるようなレイヤーを組み合わせて「学習モデル」を作成している。と言う状態です。
モデルのコンパイル
このコンパイルもせって処理が含まれています。それは「最適化関数(オプティマイザ)」と「損失関数」を設定することです。
# モデルのコンパイル
model.compile(optimizer=tf.train.AdamOptimizer(),
loss='binary_crossentropy',
metrics=['accuracy'])
損失関数に設定しているのは「binary_crossentropy」です。
検証用のデータセットを作成する
# 検証用のデータセットを作成する x_val = train_data[:10000] partial_x_train = train_data[10000:] y_val = train_labels[:10000] partial_y_train = train_labels[10000:]
ここは特に注意する点はないと思います。
訓練する
history= model.fit(partial_x_train,
partial_y_train,
epochs=40,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)fit()で学習処理を行います。
評価する
results = model.evaluate(test_data, test_labels)
print(results)最後にグラフに表示します。
fit()の返り値の「historyオブジェクト」が実行結果を保持しているようです。
評価の結果をグラフに表示します。
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
<実行結果(出力内容)>

この特定のケースでは、20回程度のエポックの後に単純にトレーニングを中止することで、過剰適合を防ぐことができます。
作成したコードはGITからダウンロードできます。
レビューの判定
上の実行した結果は検証するモデルの評価を行うもので目的の「文章を分類する」と言うところとは全く関係のない話です。そして判定の結果をどのように出力するのか→予測の結果をどのように出力するのか?を調べると・・・
ここのサイトを見て「迷宮入りしそうだな。。。」と思ったので課題として残すことにしました。
はっきりしていること
予測の結果はpredict()で表示すると言うことです。しかし、これは予測結果としてNumPy配列を返却するので意味がわからない。。。と言うところです。
使用している関数としては、以下のようなものがあることは調べがついています。
# 2値(0 or 1)
model.predict_classes(np.array([[1,1]]), batch_size=1)
# 学習の程度(0.0~1.0)
model.predict_proba(np.array([[1,1]]), batch_size=1)
# もしくは
model.predict(np.array([[1,1]]), batch_size=1)
感想
現状の理解としてはTensorFlowでの学習処理は、以下の通り
- データセットを用意する
- データセット、テストデータでの学習モデルを作る(レイヤー作成)
- 学習処理を行う(fit())
- 評価を行う
ここまでできたら、あとは実戦に投入する→画像判定や、文章の判定を行うことができるようです。まだまだ根深そうだなぁ。。。
関連ページ一覧
- Tensorflow Keras 〜初めてのKeras〜
- Tensorflow Keras Errors〜”python is not installed as a framework.”〜
- Python Tensorflow 〜初めての人工知能(TensorFlowインストール)〜
- Tensorflow Keras〜初めのトレーニング_1〜
[rakuten ids="embellir0430:10000137"]