
イントロダクション
今までは、データセットの準備やデータの中身を見ることに注力していたようですが今回は全体的な処理の流れをチュートリアルでやるようです。参考サイト
そしてもう1つ、前回までは「分類」を行なっていたのに対し今回は「回帰分析」を行うようです。実際にチュートリアルをやってみましたが「回帰分析」がよくわからなかったので今回の学習もよくわからず終いでした。
あとで回帰分析も理解したいと思います。
<今までのチュートリアル>
本題
初めに「seaborn」パッケージをインストールします。
# Use seaborn for pairplot
!pip install -q seabornしかし、自分の端末では上のコマンドでインストールできなかったので
pip install seaborn
でインストールしました。
そして、ハローワールド的にバージョン情報の表示、以下のソースを実行 ※チュートリアルのページからコピーできるやつ!
from __future__ import absolute_import, division, print_function import pathlib import pandas as pd import seaborn as sns import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers print(tf.__version__)
この後のコードも同様にコピペでいけます。ただし、tail()はprintしないと表示しないようです。
print(dataset.tail())
そして、下のグラフの表示に関しても同様で下のコードを追加してやる必要がありました。
import matplotlib.pyplot as plt ・ ・ ・ plt.show()
<実行結果>

<全体的な統計の出力結果>
# 初めの表
MPG Cylinders Displacement ... USA Europe Japan
393 27.0 4 140.0 ... 1.0 0.0 0.0
394 44.0 4 97.0 ... 0.0 1.0 0.0
395 32.0 4 135.0 ... 1.0 0.0 0.0
396 28.0 4 120.0 ... 1.0 0.0 0.0
397 31.0 4 119.0 ... 1.0 0.0 0.0
[5 rows x 10 columns]
# 全体的な統計の出力結果
count mean std ... 50% 75% max
Cylinders 314.0 5.477707 1.699788 ... 4.0 8.00 8.0
Displacement 314.0 195.318471 104.331589 ... 151.0 265.75 455.0
Horsepower 314.0 104.869427 38.096214 ... 94.5 128.00 225.0
Weight 314.0 2990.251592 843.898596 ... 2822.5 3608.00 5140.0
Acceleration 314.0 15.559236 2.789230 ... 15.5 17.20 24.8
Model Year 314.0 75.898089 3.675642 ... 76.0 79.00 82.0
USA 314.0 0.624204 0.485101 ... 1.0 1.00 1.0
Europe 314.0 0.178344 0.383413 ... 0.0 0.00 1.0
Japan 314.0 0.197452 0.398712 ... 0.0 0.00 1.0
[9 rows x 8 columns]
引き続きコピペでプログラムを組んでいきます。下は実行結果
.summaryメソッドを使用してモデルの簡単な説明を印刷する
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 64) 640 _________________________________________________________________ dense_1 (Dense) (None, 64) 4160 _________________________________________________________________ dense_2 (Dense) (None, 1) 65 ================================================================= Total params: 4,865 Trainable params: 4,865 Non-trainable params: 0 _________________________________________________________________
それではモデルを試してみてください。
10トレーニングデータから試験のバッチを取り、model.predictそれを呼び出します。
<実行結果>
array([[0.08682194]、
[0.0385334]、
[0.11662665]、
[ - 0.22370592]、
[0.1239757]、
[0.1349103]、
[0.41427213]、
[0.19710071]、
[0.01540279
]、dtype = float32)
しかし、NumPyが出力されてもよくわからん。。。と言うのは前回と同じです。
モデルを訓練する
ここもやっぱりコピペでプログラムを書きます。最後に以下のコードを追加してください。
plt.show()
<実行結果>
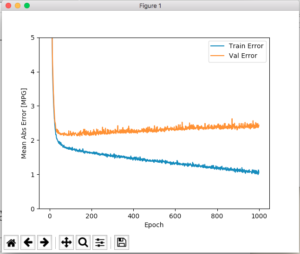
自動的にトレーニングを停止するようにメソッドを更新
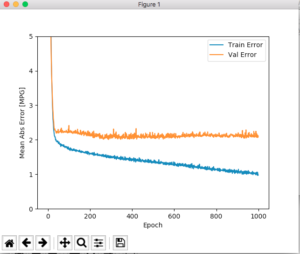
微妙な差分ですが。。。その良し悪しは「あなた次第」らしいです。
モデルがどのように機能したのか?
これまでと同様にコピペでコードを追加します。実行結果です。
Testing set Mean Abs Error: 2.03 MPG
テストの平均誤差が「2.03MPG」ある。。。
予測を行う
ここもやっぱりコピペで下が実行結果、参考サイトと違う結果になりました。どこかが間違っているように思える。。。
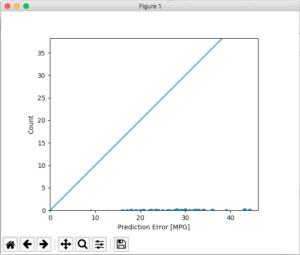
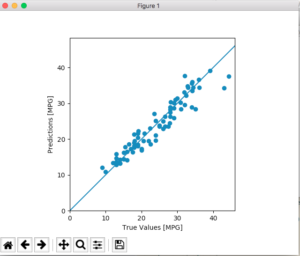
ソースを見直しました。グラフ表示の設定がまずかったようです。初めの方にある「plot_history(history)」をコメントアウトしました。

結論
「データセットの用意→モデル作成→トレーニング→予測」を行いその結果に対してどのような判断をするか?
でも、前提になるこれらの処理の結果がなんなのか?を理解しないと今までやってきたことも水の泡になりそうです(笑)