Sub Main
Dim oSheet AS Object
Dim oCell AS Object
Dim oCell2 AS Object
' ****************
' 練習用のコード
' ****************
oSheet = ThisComponent.Sheets.getByName("pref_mst")
'oCell = oSheet.getCellrangeByName("C2")
'oCell.String = "aaA" ' 文字列をセット
'
'oCell2 = oSheet.getCellrangeByName("C3")
'oCell2.String = oSheet.Name
' シート数だけシートを取得する
Dim oEnum As Object
oEnum = oSheet.createEnumeration()
While(oEnum.hasMoreElements())
'' シート取得
'セルを取得
End While
End Sub
REM ***** BASIC *****
Sub Main
dim doc as object
dim count as Integer
dim shList as object
dim sheet as object
doc = ThisComponent
count = doc.getSheets().count
shList = doc.getSheets()
' シートを順に取得する
dim root as String
root = "C:\Users\tak45\OneDrive\ドキュメント\sampleCode\Gotochi\data\"
dim fileName as String
' セルのポジション
Dim cellRpw as Integer
Dim cellColumn as integer
Dim line as String
Dim tmp as String
cellRow = 0
cellColumn = 0
Dim fileNum as Integer
fileNum = Freefile()
for i = 0 to count
' シートの取得
sheet = shList.getByIndex(i)
' 出力ファイル名
fileName = root + sheet.Name + ".csv"
' ファイルを開く
Open fileName For Output As #fileNum
tmp = ""
line = ""
' 1行分のデータを取得してファイル出力
tmp = sheet.getCellByPosition(cellRow, cellColumn).getString
if tmp <> "" then
line = tmp + ", "
else
exit for
end if
cellColumn = cellColumn + 1
While(tmp <> "")
tmp = sheet.getCellByPosition(cellColumn, cellRow).getString
if tmp <> "" then
line = line + tmp + ", "
cellColumn = cellColumn + 1
else
Dim resCount as Integer
resCount = len(line) - 2
line = Left(line, resCount)
cellRow = cellRow + 1
cellColumn = 0
Print #fileNum, line
tmp = sheet.getCellByPosition(cellColumn, cellRow).getString
line = ""
end if
WEnd
cellRow = 0
'ファイルを閉じる
Close #fileNum
if i = 2 then
exit for
end if
next i
End Sub
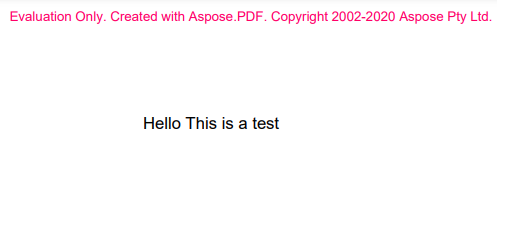
public static void main(String[] args) {
Document doc = new Document();
Page page = doc.getPages().add();
page.getParagraphs().add(new TextFragment(
"Hello This is a test"));
doc.save("Hello.pdf");
}