イントロダクション
MySQLなどのDBを使用しているときに、どうしてもネットで調べながらになるので、時間がかかる。。。
では、調べたものを一覧化しておけば、調べるのも楽だと考えました。
MySQLの文字コード
参考サイト
my.cnfを修正する。
[mysqld]
...
character-set-server=utf8 #mysqldセクションの末尾に追加
[client]
default-character-set=utf8 #clientセクションを追加
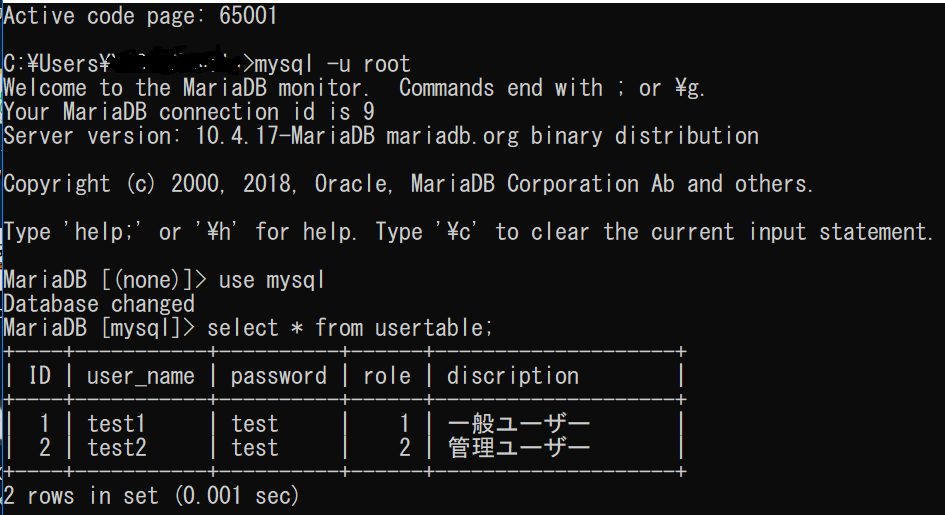
MySQLにユーザー登録
次のコマンドでユーザー登録を行いました。
-
DB確認
show databases
-
ユーザー作成
create user 'takunoji'@'localhost' identified by 'takunoji1';
-
全権限を与える
grant all previleges on . TO 'takunoji'@'localhost';
ここで、「localhost」をつけないと、コマンドで動かそうとしてもアクセスができない。。。
MySQLの設定コマンド
- charset 文字コード名: 文字コードを設定する
- コマンドプロンプトの文字コード設定(UTF-8)
chcp 65001で、コマンドプロンプトの文字コードをUTF-8に設定、その後MySQLに登録した文字(UTF-8)を表示する
SQL文法の一覧
CREATE DATABASE
参考サイトはこちらです。
CREATE DATABASE [IF NOT EXISTS] db_name
CREATE USER
参考サイトはこちらです。
CREATE USER user IDENTIFIED BY 'auth_string'
CREATE TABLE
参照先: MySQLリファレンス
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(create_definition,...)
[table_options]
[partition_options]create_definition:
col_name column_definition
| [CONSTRAINT [symbol]] PRIMARY KEY [index_type] (index_col_name,...)
[index_option] ...
| {INDEX|KEY} [index_name] [index_type] (index_col_name,...)
[index_option] ...
| [CONSTRAINT [symbol]] UNIQUE [INDEX|KEY]
[index_name] [index_type] (index_col_name,...)
[index_option] ...
| {FULLTEXT|SPATIAL} [INDEX|KEY] [index_name] (index_col_name,...)
[index_option] ...
| [CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (index_col_name,...) reference_definition
| CHECK (expr)
CREATE TABLE fravors (id int not null primary key auto_increment, name text);
実行SQLサンプル
テーブル作成
create table students (student_no not null primary key, name varchar(20), japanese int, math int, english int);
データの登録
insert into students (student_no, name, japanese, math, english) values(2001, '阿部正幸', 80, 90, 60);
insert into students (student_no, name, japanese, math, english) values(2002, '今井 美紀子', 60, 30, 70);
insert into students (student_no, name, japanese, math, english) values(2003, '上野 英次', 70, 100, 90);テーブルの結合
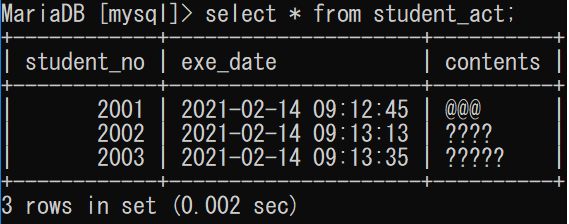
select * from students a1, student_act b1 where a1.student_no = b1.student_no;
studentsテーブルとstudent_actテーブルを「student_no」をキーにして結合します。
この条件がない時は下のように、データが重複してしまいます。
select * from students a1, student_act b1;

ここでの「条件」とは、Whereの部分です。
where a1.student_no = b1.student_noこの条件を付けることでstudentsテーブルとstudent_actテーブルのデータの関連性を適用しています。
STUDENTSテーブル

STUDENT_ACTテーブル
ALTER TABLE
参照先:MySQLリファレンス
ALTER [ONLINE|OFFLINE] [IGNORE] TABLE tbl_name
[alter_specification [, alter_specification] ...]
[partition_options]
「[]」で囲っている部分は必須ではないので、fravorsテーブルを修正したいときには、次のようなSQLになります。
ALTER TABLE fravors ...
そして、テーブルにどのような変更をするのか?というコマンド(SQL)は次のようになっています。
alter_specification:
table_options
| ADD [COLUMN] col_name column_definition
[FIRST | AFTER col_name ]
| ADD [COLUMN] (col_name column_definition,...)
| ADD {INDEX|KEY} [index_name]
[index_type] (index_col_name,...) [index_option] ...
| ADD [CONSTRAINT [symbol]] PRIMARY KEY
[index_type] (index_col_name,...) [index_option] ...
| ADD [CONSTRAINT [symbol]]
UNIQUE [INDEX|KEY] [index_name]
[index_type] (index_col_name,...) [index_option] ...
| ADD FULLTEXT [INDEX|KEY] [index_name]
(index_col_name,...) [index_option] ...
| ADD SPATIAL [INDEX|KEY] [index_name]
(index_col_name,...) [index_option] ...
| ADD [CONSTRAINT [symbol]]
FOREIGN KEY [index_name] (index_col_name,...)
reference_definition
| ALGORITHM [=] {DEFAULT|INPLACE|COPY}
| ALTER [COLUMN] col_name {SET DEFAULT literal | DROP DEFAULT}
| CHANGE [COLUMN] old_col_name new_col_name column_definition
[FIRST|AFTER col_name]
| LOCK [=] {DEFAULT|NONE|SHARED|EXCLUSIVE}
| MODIFY [COLUMN] col_name column_definition
[FIRST | AFTER col_name]
| DROP [COLUMN] col_name
| DROP PRIMARY KEY
| DROP {INDEX|KEY} index_name
| DROP FOREIGN KEY fk_symbol
| DISABLE KEYS
| ENABLE KEYS
| RENAME [TO|AS] new_tbl_name
| ORDER BY col_name [, col_name] ...
| CONVERT TO CHARACTER SET charset_name [COLLATE collation_name]
| [DEFAULT] CHARACTER SET [=] charset_name [COLLATE [=] collation_name]
| DISCARD TABLESPACE
| IMPORT TABLESPACE
| FORCE
| ADD PARTITION (partition_definition)
| DROP PARTITION partition_names
| TRUNCATE PARTITION {partition_names | ALL}
| COALESCE PARTITION number
| REORGANIZE PARTITION partition_names INTO (partition_definitions)
| EXCHANGE PARTITION partition_name WITH TABLE tbl_name
| ANALYZE PARTITION {partition_names | ALL}
| CHECK PARTITION {partition_names | ALL}
| OPTIMIZE PARTITION {partition_names | ALL}
| REBUILD PARTITION {partition_names | ALL}
| REPAIR PARTITION {partition_names | ALL}
| REMOVE PARTITIONING
fravorsテーブルにカラム(image BLOB型データ)を追加するときは次のようになります。
ALTER TABLE fravors add column image blob;
テーブル定義の確認方法
SHOW FULL COLUMNS FROM テーブル名
SELECT文
参照先: MySQLリファレンス
select * from fravors;
まだまだ更新します。
でわでわ。。。