イントロダクション
前回は、LineChartを使用して折れ線グラフを作成しました。他にも〜Chartクラスを漁ってみましたが適当なものが見つからなかったのでCanvasクラスを使用しようと思います。
<漁ってみたクラス>
- JavaFX グラフ描画〜AreaChartを使う〜
- JavaFX LineChart 〜グラフを描く、ワンポイントレッスン的な〜
Canvasを使う
ラップされたクラスを使用すると楽にできます。。。駄菓子菓子「細かい調節が効かない」という欠点を持っています。これはJavaに限らずPthon, Ruby, JavaSriptなどの高レベルAPIと呼ばれるプログラミング言語では潜在するものです。その代わり、楽に作れるのがポイント!
そして、Javaはちょっと特殊で「高レベルAPI」と呼ばれるものと「低レベルAPI」と呼ばれるものが混在します。Pythonでも似た様なことをいうときがありますが。。。
早い話が
画面上のグラフの土台から全部描いてしまおうというわけです。
GraphcContextを使う
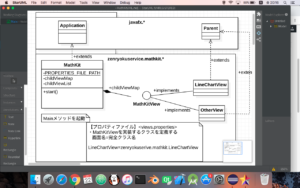
結論から言うとこんな感じでグラフの土台を作成しました。

X軸とY軸はちょいと太めの線で描画しています。そして、補助線は薄い色で描画しています。現状では、4分割する様な形で補助線を引いていますが、これはいじれるようになっています。
<コード>
public class Graphics2DView extends Parent implements MathKitView {
/* (non-Javadoc)
* @see zenryokuservice.mathkit.MathKitView#loadView(javafx.scene.layout.VBox)
*/
@Override
public Parent loadView(VBox root) {
Canvas canvas = new Canvas(600, 600);
GraphicsContext ctx = canvas.getGraphicsContext2D();
// グラフの土台を作る
drawGraphBase(ctx, root);
root.getChildren().add(canvas);
return root;
}
/**
* グラフの土台になる部分を描画します。
* @param ctx Canvasから取得したクラス
* @param root レイアウトクラス(シーン追加する)
*/
private void drawGraphBase(GraphicsContext ctx, VBox root) {
ctx.setStroke(Color.BLACK);
ctx.setLineWidth(2.0);
// X軸
ctx.strokeLine(0, 250, 500, 250);
// Y軸
ctx.strokeLine(250, 0, 250, 500);
// マスを作る
double span = 500 / 4;
ctx.setLineWidth(0.5);
for (int i = 0; i <= 4; i++) {
if (i == 0 || i == 2 || i == 4) {
continue;
}
// 縦の補助線
ctx.strokeLine(i * span, 0, i * span, 500);
// 横の補助線
ctx.strokeLine(0, i * span, 500, i * span);
}
}
}
※上のコードだけで描画できるのはそう言う仕組みを作ったからです。その仕組みはこちらを参照ください。Gitからダウンロードもできます。(ここはファイルの差分を表示しています。)
次回は、関数を描画しようと思います。
でわでわ。。。
[rakuten ids="book:18903401"]